
Databases are the backbone of modern computing, serving as the repositories for the data that powers everything from the simplest websites to the most complex analytical software. They come in many shapes and sizes, tailored to different kinds of data and use cases. At their core, databases store, retrieve, and manage data efficiently and reliably, making them indispensable in the digital age.
The primary distinction in database technology is between relational and non-relational databases. Relational databases, also known as SQL databases, organize data into tables which are linked to each other through relationships, making them highly structured and suitable for complex queries. Non-relational databases, on the other hand, store data in a more flexible format such as key-value pairs, documents, wide-column stores, or graphs, catering to a variety of data types and structures not suited for table-based storage.
The choice between a relational and a non-relational database hinges on the specific needs of an application, including the nature of the data, the expected scale, and the complexity of the queries. Relational databases excel in transactions requiring atomicity, consistency, isolation, and durability (ACID), while non-relational databases offer scalability and flexibility to handle large volumes of unstructured data. This distinction is crucial for developers and businesses alike as they navigate the digital landscape, seeking the most effective ways to store and process their valuable data.

Database Basics
Core Concepts
Definition of a Database
A database is a structured collection of data. It serves as the foundation for storing and retrieving information in a systematic way. Databases are critical in various applications, providing the means to manage, organize, and use data effectively. They enable users and applications to access data quickly, ensuring that information is both available and secure.
Data Management Essentials
Data management is the practice of collecting, keeping, and using data securely, efficiently, and cost-effectively. The key elements include:
- Data Storage: The method of saving data in digital form.
- Data Retrieval: The process of accessing and retrieving data from where it is stored.
- Data Security: Protecting data from unauthorized access and data breaches.
- Data Integrity: Ensuring the accuracy and consistency of data over its lifecycle.
Database Types
Overview of Database Categories
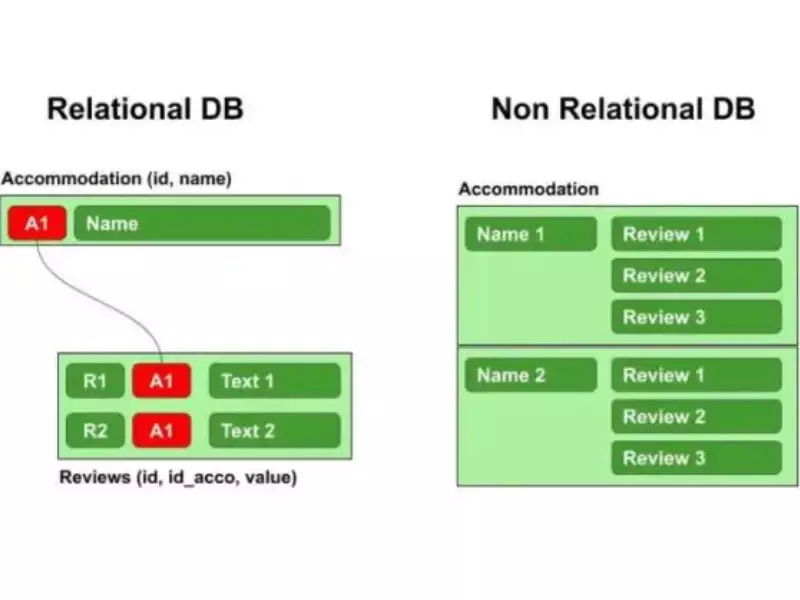
Databases can be broadly categorized into relational and non-relational databases. Relational databases use a structured query language (SQL) for defining and manipulating data, which is organized into tables. Non-relational databases, also known as NoSQL databases, store data in formats that are not strictly table-based. They include document, key-value, wide-column, and graph databases.
Relational Databases
Definition and Structure
Explanation of Relational Databases
A relational database is a type of database that stores and provides access to data points that are related to one another. It organizes data in tables, which represent entities. Each table has rows and columns, where rows represent records, and columns represent attributes.
Table-based Structure
The structure is based on tables, making it easy to understand and use. Each table is identified by a name and contains records (rows) with data. The relationship between tables is established through foreign keys.
Key Features
ACID Properties
Relational databases adhere to ACID properties:
- Atomicity: Each transaction is fully completed or not done at all.
- Consistency: Ensures data is consistent before and after a transaction.
- Isolation: Transactions are processed independently.
- Durability: Once a transaction is committed, it will remain so, even in the event of a system failure.
SQL for Data Manipulation
SQL (Structured Query Language) is used to interact with a relational database. It is used for:
- Querying data
- Updating data
- Inserting data
- Deleting data
Use Cases
Suitable Scenarios for Using Relational Databases
Relational databases are ideal for applications requiring complex transactions and where data integrity is crucial. Examples include:
- Financial systems
- Customer relationship management (CRM) systems
- E-commerce platforms
Non-Relational Databases
Definition and Types
Explanation of Non-Relational Databases
Non-relational databases, or NoSQL databases, store data in formats other than the tabular relations used in relational databases. They are designed for scalability and flexibility.
Types: Document, Key-Value, Wide-Column, Graph
- Document: Stores data in document-oriented formats, typically JSON.
- Key-Value: Stores data as a collection of key-value pairs.
- Wide-Column: Stores data in tables, rows, and dynamic columns.
- Graph: Uses graph structures for semantic queries, with nodes, edges, and properties to represent and store data.
Key Features
Flexibility and Scalability
Non-relational databases are highly flexible and scalable. They can handle a large volume of unstructured data and grow with the application’s needs.
Schema-less Data Model
These databases often follow a schema-less data model, allowing the structure of the data to change without affecting existing data. This is particularly useful for applications that need to evolve over time.
Use Cases
Ideal Scenarios for Non-Relational Databases
Non-relational databases are suitable for:
- Storing large volumes of unstructured data
- Rapid development and deployment of applications
- Applications requiring real-time analytics and processing
Comparative Analysis
Performance
Speed and Efficiency in Various Use Cases
Relational databases excel in complex query processing, offering high efficiency when dealing with structured data and relationships. They are optimized for ACID transactions, ensuring data integrity and consistency, which is crucial in applications like banking and online retail.
On the other hand, non-relational databases are designed for speed when handling large volumes of unstructured or semi-structured data. They shine in scenarios where data models are flexible or undefined, offering rapid data retrieval by avoiding the overhead of relational schema and join operations.
Scalability
Handling Large-scale Data
Non-relational databases are inherently more scalable, both vertically and horizontally, than relational databases. They can easily distribute data across multiple servers to manage large datasets and high user loads, making them ideal for big data applications and cloud services.
Relational databases, while traditionally more challenging to scale, have evolved with distributed database technologies and cloud solutions to offer considerable scalability, albeit often at higher complexity and cost.
Complexity
Data Model and Query Complexity
Relational databases have a complex data model, requiring a predefined schema and understanding of SQL for data manipulation and querying. This complexity can provide power and flexibility but requires significant expertise.
In contrast, non-relational databases often offer simpler, more intuitive data models such as key-value pairs or documents, reducing the barrier to entry for developers. The trade-off is that they may not natively support as complex querying capabilities as SQL databases.
Flexibility
Schema Rigidity vs. Flexibility
The schema in relational databases is rigid, making it challenging to adapt to changes in data structure without downtime or complex migrations. This rigidity ensures data consistency and integrity but can hinder rapid development and iteration.
Non-relational databases offer schema flexibility, allowing for on-the-fly modifications to the data structure. This adaptability is particularly beneficial in agile development environments and for applications that evolve quickly.
Cost
Initial and Scaling Costs Comparison
Relational databases may have higher initial costs due to licensing fees for commercial software and the need for specialized skills to design and maintain the database schema. Scaling up can also introduce significant costs, particularly for vertical scaling or when complex distributed architectures are required.
Conversely, non-relational databases often have lower initial costs, particularly with open-source options. They are designed for horizontal scaling, which can be more cost-effective, especially when deployed in cloud environments that offer pay-as-you-go scalability.
Selection Criteria
Assessing Project Needs
Choosing the right database involves evaluating:
- Data structure: Is the data highly structured or unstructured?
- Size: Will the database need to store large volumes of data?
- Speed requirements: Are fast read and write operations critical?
Consistency vs. Availability
CAP theorem considerations impact database selection. Relational databases often prioritize consistency and partition tolerance, ensuring data accuracy across distributed systems. Non-relational databases may prioritize availability and partition tolerance, focusing on providing continuous access to data over strict consistency.
Transaction Requirements
ACID properties (Atomicity, Consistency, Isolation, Durability) are hallmark features of relational databases, making them suitable for applications requiring reliable transactions.
Non-relational databases often follow the BASE model (Basically Available, Soft state, Eventual consistency), which is more flexible but offers less strict consistency guarantees. This trade-off can be acceptable or even preferable for applications where availability is prioritized over immediate consistency.
Future Scalability
Long-term data management strategies should consider the ease of scaling the database. Non-relational databases offer more straightforward horizontal scaling, while relational databases require more careful planning for scale, often involving sharding or replication.
Real-world Applications
Relational Database Examples
Industries like banking, healthcare, and e-commerce rely on relational databases for applications where transaction integrity and data relationships are critical.
Non-Relational Database Examples
Social networks, content management systems, and IoT applications often utilize non-relational databases to manage large volumes of diverse data and support rapid development.
Transitioning Between Databases
Migration Strategies
Transitioning between databases requires a clear understanding of the target and source data models. Strategies include:
- Data mapping
- Migration scripting
- Testing and validation
Tools and Techniques
Solutions for seamless transition include migration tools that automate the conversion of schemas and data, as well as services offered by cloud providers to simplify the process.
Future Trends
Advancements in Database Technology
Emerging trends include serverless databases for reducing operational complexity, AI and machine learning integration for predictive analytics, and multi-model databases that combine relational and non-relational features.
Predictions for Relational vs. Non-Relational
The future will likely see a convergence of features, with relational databases becoming more flexible and non-relational databases adding more robust querying and transaction capabilities. The emphasis will be on performance, scalability, and ease of use, regardless of the underlying technology.
FAQs
What is a relational database?
A relational database is a type of database that stores and provides access to data points that are related to one another. It organizes data into tables which consist of rows and columns, with each table representing a different type of entity. The relationships between tables are defined through foreign keys, allowing for the structured querying and analysis of complex datasets using a language such as SQL. This structure enables relational databases to handle a wide variety of transactions and queries in a consistent and reliable manner.
How does a non-relational database work?
Non-relational databases, also known as NoSQL databases, store data in formats other than the tabular relations used in relational databases. These can include key-value stores, document databases, wide-column stores, and graph databases. Each type serves different needs, from simple retrieval operations to the management of highly connected data. Non-relational databases are designed for scalability and flexibility, allowing them to handle large volumes of unstructured or semi-structured data efficiently.
When should I use a relational database?
A relational database is ideal for applications that require complex transactions, data integrity, and structured querying capabilities. They are particularly well-suited for scenarios where the data relationships are well-defined and where operations require the ACID properties (Atomicity, Consistency, Isolation, Durability). Examples include financial systems, inventory management, and other applications where data accuracy and consistency are critical.
Why choose a non-relational database?
Choose a non-relational database when working with large volumes of unstructured or semi-structured data, or when the application demands high scalability and flexibility. Non-relational databases are optimized for speed in data retrieval and storage, making them ideal for real-time applications, big data analytics, and applications that require frequent changes to the data schema. They offer a more adaptable and performance-oriented solution for these types of use cases.
Conclusion
The decision between a relational and a non-relational database is foundational to the architecture of any data-driven application. Each type offers distinct advantages and limitations, informed by decades of development and application in the field. Relational databases bring structure and transactional integrity, making them indispensable for applications requiring rigorous data consistency and complex queries. Non-relational databases, with their flexibility and scalability, are tailored for the vast, unstructured datasets that characterize the big data era.
Ultimately, the choice rests on the specific requirements of the application, including the nature of the data, the expected load, and the types of queries it will support. Understanding the differences between these database technologies enables developers and businesses to make informed decisions, laying a solid foundation for their data management strategy. As technology continues to evolve, the lines between these databases may blur, but their core distinctions will remain a critical consideration in the design and implementation of effective, efficient data systems.