
Databases stand as the backbone of modern computing, essential for storing, organizing, and accessing data efficiently. In the realm of database technology, the distinction between relational and non-relational databases marks a fundamental divide, each catering to different needs and use cases. This differentiation not only influences how data is stored and managed but also affects scalability, performance, and application design.
Relational databases organize data into tables, which are linked to each other through relationships. This structure enables complex queries and transactions, ensuring data integrity and consistency through the ACID properties. In contrast, non-relational databases, also known as NoSQL databases, offer a more flexible data storage approach, including document, key-value, graph, and wide-column stores. These databases are designed to scale out by distributing data across multiple servers, making them ideal for handling large volumes of unstructured data and real-time applications.
Understanding these differences is crucial for developers, data architects, and businesses to make informed decisions about which database technology to adopt. The choice between relational and non-relational databases can significantly impact the efficiency, scalability, and overall success of technology projects. By examining the characteristics, advantages, and use cases of each, stakeholders can align their database selection with their specific requirements and goals.

Database Basics
In the realm of software development and data management, databases stand as the cornerstone of information storage and retrieval. They are pivotal for both small-scale applications and large-scale enterprise solutions, facilitating the organized storage of data that can be easily accessed, managed, and updated. Two primary types of databases have emerged over the years, each serving distinct needs and use cases: Relational Databases (RDBMS) and Non-Relational Databases (NoSQL).
Types of Databases
Relational Databases (RDBMS)
Relational databases are based on the relational model, an intuitive and straightforward way of representing data in tables. Each table, which is akin to a spreadsheet, consists of rows and columns, with each row representing a unique record and each column representing a data field. This model allows for data relationships to be easily established through the use of foreign keys, making relational databases ideal for applications where integrity and accuracy of data relationships are crucial.
Non-Relational Databases (NoSQL)
Non-relational databases, commonly referred to as NoSQL databases, diverge from the traditional table-based structure. They are designed to handle a wide array of data types including document-oriented, key-value pairs, graph databases, and wide-column stores. NoSQL databases excel in scenarios requiring flexibility, scalability, and the ability to store unstructured or semi-structured data.
Core Concepts
Data Storage Models
Data storage models are fundamental in distinguishing between relational and non-relational databases. Relational databases utilize a structured query language (SQL) for defining and manipulating data, which is strictly organized into tables. Non-relational databases, on the other hand, offer a schema-less data storage solution, allowing data to be stored in a format that is best suited for the specific type of data being handled.
Schema vs. Schema-less
The concept of schema in databases refers to the structure of the database, specifically how data is organized. Relational databases are schema-based, meaning the structure of the database (tables, columns, and the data type of each column) must be defined before data can be added. Non-relational databases are schema-less, providing the flexibility to store data without predefining its structure, which can significantly reduce development time and allow for more dynamic data storage.
Relational Databases
Definition and Structure
Relational Databases Management Systems (RDBMS) are defined by their use of a table-based structure, where data is stored in rows and columns. This structure facilitates a direct relationship among stored data, enabling complex queries and transactions that maintain data integrity through ACID properties (Atomicity, Consistency, Isolation, Durability).
Table-based Data Structure
The table-based data structure of RDBMS allows for precise data modeling and relationship definition among the stored data entities. This organization supports complex queries and data analysis, making it ideal for applications requiring rigorous data integrity and relationship management.
SQL for Data Manipulation
Structured Query Language (SQL) is the standardized language used in RDBMS for creating, manipulating, and retrieving data. SQL provides a powerful and flexible toolset for data manipulation, allowing developers to perform complex queries, data analytics, and management tasks efficiently.
Advantages
ACID Properties
RDBMS are known for their strict adherence to ACID properties, ensuring reliable data integrity through transactions. This makes them ideal for financial applications, inventory systems, and any other domain where data accuracy and consistency are paramount.
Standardized Language (SQL)
The use of a standardized query language (SQL) is a significant advantage, making RDBMS widely accessible and understandable by developers. SQL’s standardization across different RDBMS platforms allows for portability and interoperability of database skills.
Use Cases
Transactions and Banking
RDBMS are the backbone of financial systems where transactions, balance sheets, and customer data need to be managed with utmost accuracy and reliability.
Established Business Systems
Traditional business systems such as ERP, CRM, and inventory management rely heavily on relational databases for structured data storage and integrity.
Limitations
Scalability Challenges
While RDBMS provide robust data integrity and relationships, they face scalability challenges in handling massive volumes of data or rapidly growing datasets, particularly in distributed computing environments.
Fixed Schema
The fixed schema requirement of relational databases can be a limitation in agile development environments, where the data model may evolve as the application develops.
Non-Relational Databases
Definition and Structure
Non-relational databases, or NoSQL databases, break away from the traditional relational database model by offering a schema-less data storage approach. This flexibility allows for a variety of data types to be stored and managed efficiently, catering to the needs of modern applications that handle big data, real-time analytics, and unstructured data.
Types: Document, Key-Value, Graph, Wide-Column
NoSQL databases can be categorized into four main types, each designed to serve specific data storage and retrieval needs:
- Document databases store data in document-like structures (JSON, BSON) and are ideal for storing, retrieving, and managing document-oriented information.
- Key-value stores are the simplest form of NoSQL databases, storing data as a collection of key-value pairs, suitable for caching and storing session data.
- Graph databases are designed for data whose relationships are best represented as a graph and are ideal for social networks, recommendation engines, and network analysis.
- Wide-column stores efficiently store data in columns rather than rows, making them suitable for analyzing large datasets.
Advantages
Flexibility and Scalability
The schema-less design and diverse data models of NoSQL databases offer unparalleled flexibility and scalability, accommodating a wide variety of data types and structures.
Schema-less Design
NoSQL databases do not require a fixed schema, allowing for the storage of unstructured or semi-structured data. This adaptability makes them ideal for applications that need to evolve rapidly or handle varied data formats.
Use Cases
Big Data Applications
NoSQL databases are particularly well-suited for big data applications and analytics, where they can store and process vast amounts of unstructured data efficiently.
Real-time Analytics
The flexibility and performance of NoSQL databases make them ideal for real-time analytics and applications that require fast data access, such as content management systems and e-commerce platforms.
Limitations
Lack of Standardization
The diverse nature of NoSQL databases means a lack of standardization, which can lead to complexity in development and management compared to the uniformity of SQL in relational databases.
Transaction Support
While some NoSQL databases have begun to offer transactional support, traditionally, they have lacked the comprehensive ACID transaction capabilities of relational databases, making them less suitable for applications where transaction integrity is critical.
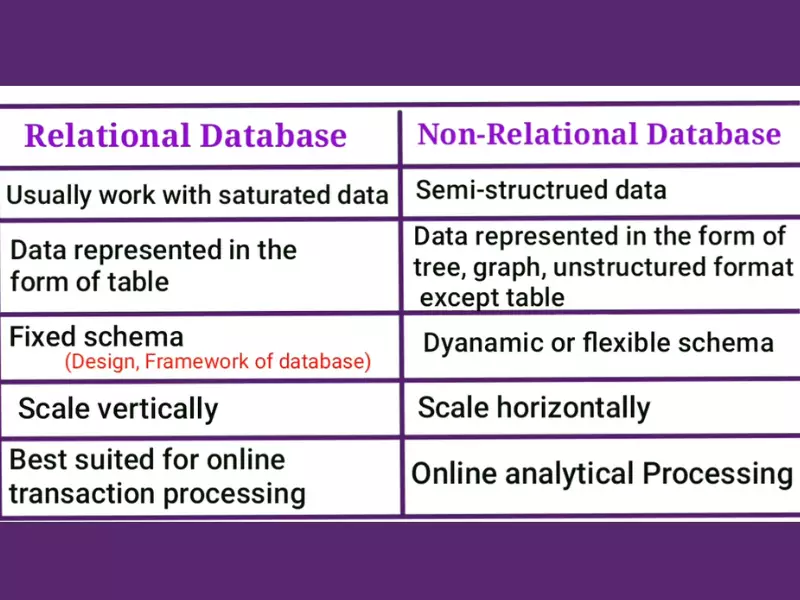
Comparing Performance
Speed and Efficiency
When comparing relational and non-relational databases, speed and efficiency are pivotal metrics. Non-relational databases often excel in read and write speeds, especially in environments with large volumes of data and high concurrency demands. This is due to their schema-less nature and the ability to distribute data across multiple servers easily. On the other hand, relational databases are optimized for complex queries involving multiple tables, where the integrity and relationships of data are crucial. However, these operations can be more time-consuming, affecting the overall performance in high-demand scenarios.
Read and Write Speeds
Non-relational databases generally offer faster write speeds because they don’t require data to conform to a strict schema and can easily distribute writes across a cluster of servers. Relational databases, while potentially slower for writes due to transactional integrity and normalization, often provide more efficient read operations for complex queries that involve multiple tables and relationships.
Scalability Comparison
Scalability is a significant factor in database performance. Non-relational databases are inherently designed for horizontal scalability, meaning they can easily expand by adding more servers. This scalability makes them suitable for applications with large, distributed data sets. Relational databases, traditionally, excel in vertical scalability but have evolved to offer more robust horizontal scaling solutions through techniques like sharding, albeit with more complexity.
Data Modeling
The choice between structured vs. unstructured data and the method of relationship handling can significantly affect the performance and scalability of a database.
Structured vs. Unstructured Data
Relational databases are inherently designed for structured data, which follows a predefined schema. This makes them highly efficient for scenarios where data integrity and relationships are key. Non-relational databases shine with unstructured or semi-structured data, such as JSON documents, allowing for more flexibility in data storage and retrieval, which can lead to performance gains in specific scenarios.
Relationship Handling
Relational databases manage relationships between data through foreign keys and join operations, which can be powerful but may impact performance as the size and complexity of the data grow. Non-relational databases handle relationships differently, often embedding related data within a single document or using references, which can simplify retrieval operations and improve performance but might complicate data integrity and consistency.
Selecting a Database
Choosing the right database technology involves understanding the specific needs of your application, including the type and volume of data you’ll be working with, and the scalability requirements.
Factors to Consider
- Data type and volume: Consider whether your application requires structured or unstructured data storage.
- Scalability needs: Evaluate if your application demands horizontal scalability to handle large volumes of data efficiently.
Migration Considerations
Transitioning from relational to non-relational databases involves careful planning and consideration.
From Relational to Non-Relational
The move often aims to leverage the scalability and flexibility of non-relational databases. However, it requires a re-evaluation of data modeling practices to fit a schema-less structure and may involve significant changes in application code to adapt to different querying methods.
Challenges and Strategies
- Data Migration: Ensuring a smooth transition of data between different database models can be challenging. Utilizing intermediary data formats like JSON or CSV and leveraging migration tools can facilitate the process.
- Application Compatibility: Applications built around relational database structures may require significant refactoring to interact effectively with non-relational databases. Adopting microservices or API layers can help mitigate these issues by abstracting the database layer.
Future Trends
The database technology landscape is continuously evolving, with new models and capabilities emerging to meet the changing needs of modern applications.
Evolution of Database Technologies
New Database Models
Emerging database technologies are blending the lines between relational and non-relational models, offering multi-model databases that can handle various data types and structures efficiently. These advancements promise more flexibility and scalability while maintaining data integrity and relationship management capabilities.
Integration and Interoperability
Increased focus on integration and interoperability among different database systems is leading to more robust data ecosystems. This allows applications to leverage the strengths of both relational and non-relational databases within the same architecture, optimizing performance and scalability.
Impact on Industries
Data-driven Decision Making
The ability to store, process, and analyze large volumes of diverse data efficiently is empowering organizations to make more informed decisions. This data-driven approach is transforming industries, from healthcare to finance, by enabling more precise predictions, personalized services, and improved operational efficiency.
Personalization and User Experience
Advancements in database technologies are facilitating the delivery of personalized content and services to users by enabling the real-time analysis of user data. This personalization is enhancing the user experience across digital platforms, driving engagement, and loyalty.
FAQs
What is a relational database?
A relational database is a type of database that structures data into tables, which are then linked based on relationships among them. This setup allows for efficient data retrieval through SQL queries, supporting transactions and complex operations with a strong emphasis on data integrity and relationships.
How does a non-relational database differ from a relational database?
Non-relational databases, or NoSQL databases, differ from relational databases in their data storage model. They do not use tables with rows and columns but instead store data in formats like documents, key-value pairs, graphs, or wide-columns. These databases are designed for scalability and flexibility, handling large volumes of unstructured or semi-structured data efficiently.
When should I use a relational database?
A relational database is ideal for applications requiring complex transactions, data integrity, and structured data organization. They are suited for scenarios where relationships among data entities need to be maintained, such as financial systems, customer relationship management (CRM) systems, and other applications requiring consistent, ACID-compliant transactions.
Can I migrate from a relational to a non-relational database?
Yes, it is possible to migrate from a relational to a non-relational database. However, this process involves careful planning and consideration of data modeling, as the data structures between these database types are fundamentally different. The migration strategy depends on the specific requirements, such as scalability needs, the nature of the data, and the desired flexibility in data schema.
Conclusion
The decision between choosing a relational or non-relational database hinges on the specific needs of a project, including the nature of the data, the required scalability, and the complexity of the data relationships. Relational databases offer the advantages of transactional integrity, complex query capabilities, and a structured approach to data management. In contrast, non-relational databases provide flexibility, scalability, and efficiency in handling large volumes of unstructured data and real-time processing.
Navigating the landscape of database technology requires a clear understanding of the inherent strengths and limitations of each type. By considering the unique characteristics and use cases of relational and non-relational databases, organizations can adopt the most suitable database architecture, paving the way for innovative applications and services that meet the evolving demands of the digital world.